Reproducing the Website Analyses
2026-01-13
Source:vignettes/recreating_analyses.Rmd
recreating_analyses.RmdThe [Salem Witchcraft Website] (https://www2.tulane.edu/~salem/index.html) presents a number of data analyses and explains how to reproduce them using Excel. This vignette will document how to as closely as possible reproduce those analyses using R. In some cases the analyses will be extended in order to illustrate points in the website text that were not easily expressible in Excel.
While the website has seven data sets, the package has only 5. This is because R makes it relatively simple to manipulate the data and also because this organization is more in line with how social scientists would likely create a data set today.
As is always true in R, there are many different ways to do the same thing. If you are using this for teaching purposes you will likely want to use the approach that most closely matches what you are doing in your course and what your goals are for students to work on their own analyses. The focus of this document is on use of ggplot2 for graphing and in subsequent iterations will also illustrate use of the base R plotting system. There are some examples that use the tidyverse for analysis and some that use base R. However, even within these major groupings there are many ways to acheive the same goals. We have aimed to present ways to do this that are relatively accessible to people who have not used R extensively.
Many of the analyses presented are graphical and so that will be the focus here. However some preprocessing will also be illustrated.
This version does not yet include spatial analysis, but that is on the roadmap.
For the ggplots this theme is being used in may cases.
salem_theme <- theme(axis.text.x = element_text(angle = 45, vjust = .5))Accusations and Executions
The website includes displays of the distribution by month.
Histogram and frequency table of accusations by month
ggplot(data = accused_witches) +
aes(x = Month.of.Accusation.Name) +
geom_bar() +
labs(title = "Accusations by month", x = "Month") +
scale_x_discrete(drop = FALSE) +
salem_theme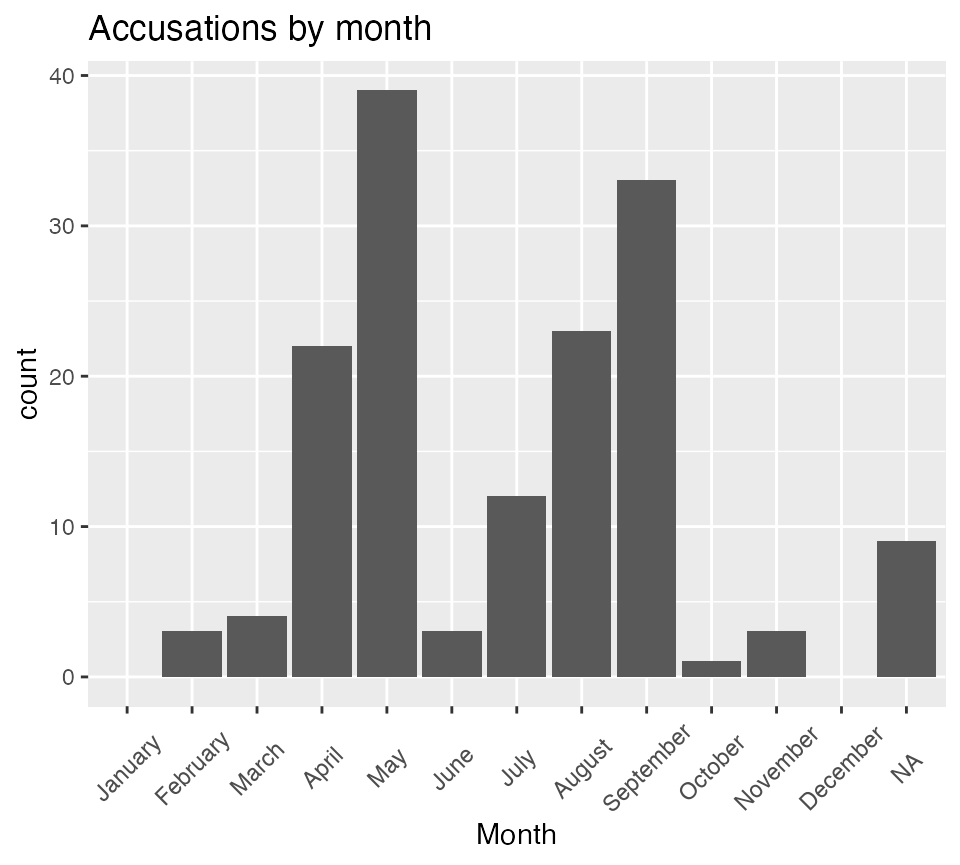
table(accused_witches$Month.of.Accusation.Name, useNA = "ifany",
dnn = "Month") |> kable(caption = "Accusations by Month")| Month | Freq |
|---|---|
| January | 0 |
| February | 3 |
| March | 4 |
| April | 22 |
| May | 39 |
| June | 3 |
| July | 12 |
| August | 23 |
| September | 33 |
| October | 1 |
| November | 3 |
| December | 0 |
| NA | 9 |
Cumulative accusations by month
ggplot(data = accused_witches) +
aes(x = as.numeric(Month.of.Accusation.Name)) +
stat_ecdf(na.rm = TRUE, geom = "line") +
labs(title = "Cumulative accusations by month", x = "Month",
y = "Cumulative Accusations") +
scale_x_continuous(breaks = c(1:12),
labels = c("Jan", "Feb", "Mar", "Apr", "May",
"Jun", "Jul","Aug", "Sept", "Oct", "Nov", "Dec") )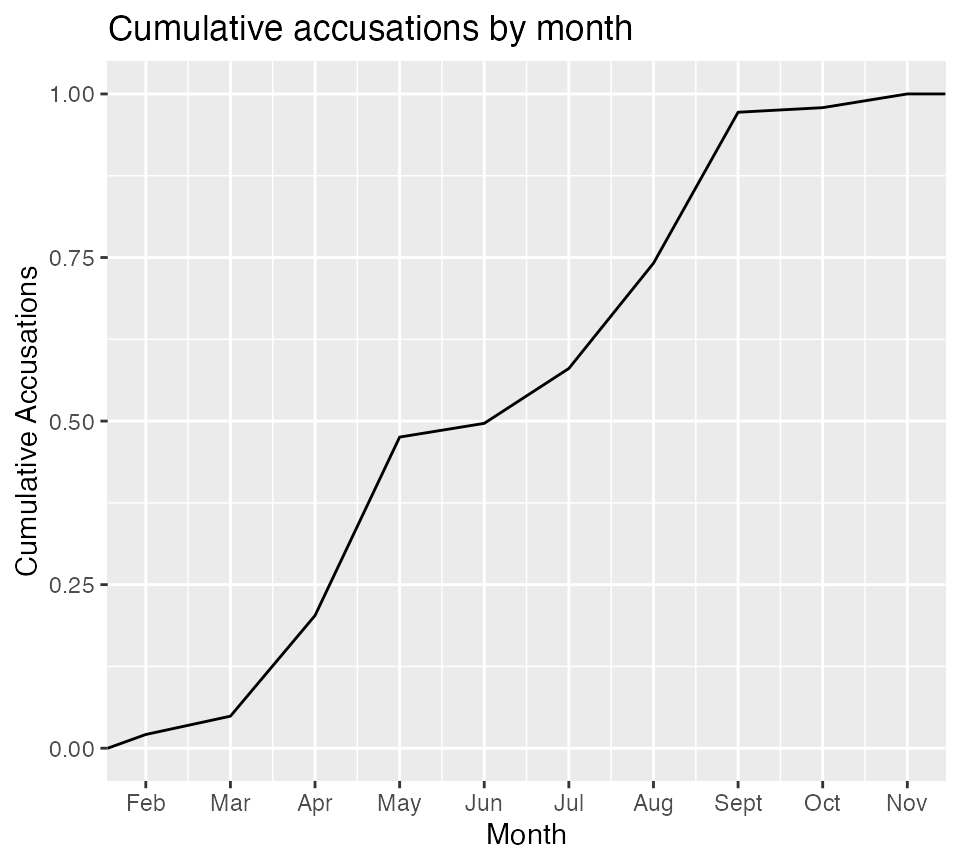
| x | |
|---|---|
| January | 0 |
| February | 3 |
| March | 7 |
| April | 29 |
| May | 68 |
| June | 71 |
| July | 83 |
| August | 106 |
| September | 139 |
| October | 140 |
| November | 143 |
| December | 143 |
An alternative approach using dplyr that provides some other options. This approach would also let you add other variables to the new monthly data, whether the number of executions or other data you collect. One advantage of this approach is that it is easier to create a Pareto Histogram as displayed on the website. These examples show three possible ways to display the Pareto histogram. As usual there are other approaches.
monthly_accusations <- accused_witches |>
filter(!is.na(Month.of.Accusation)) |>
group_by(Month.of.Accusation.Name) |>
summarize(number = n()) |>
mutate(cumulative = cumsum(number) )
monthly_accusations |> kable(caption = "Accusations by Month")| Month.of.Accusation.Name | number | cumulative |
|---|---|---|
| February | 3 | 3 |
| March | 4 | 7 |
| April | 22 | 29 |
| May | 39 | 68 |
| June | 3 | 71 |
| July | 12 | 83 |
| August | 23 | 106 |
| September | 33 | 139 |
| October | 1 | 140 |
| November | 3 | 143 |
ggplot(data = monthly_accusations) +
aes(x = Month.of.Accusation.Name, y = cumulative, group =1) +
geom_col(aes(y = number)) +
geom_line() +
labs(title = "Frequency and Cumulative Frequency of Accusations by Month") +
salem_theme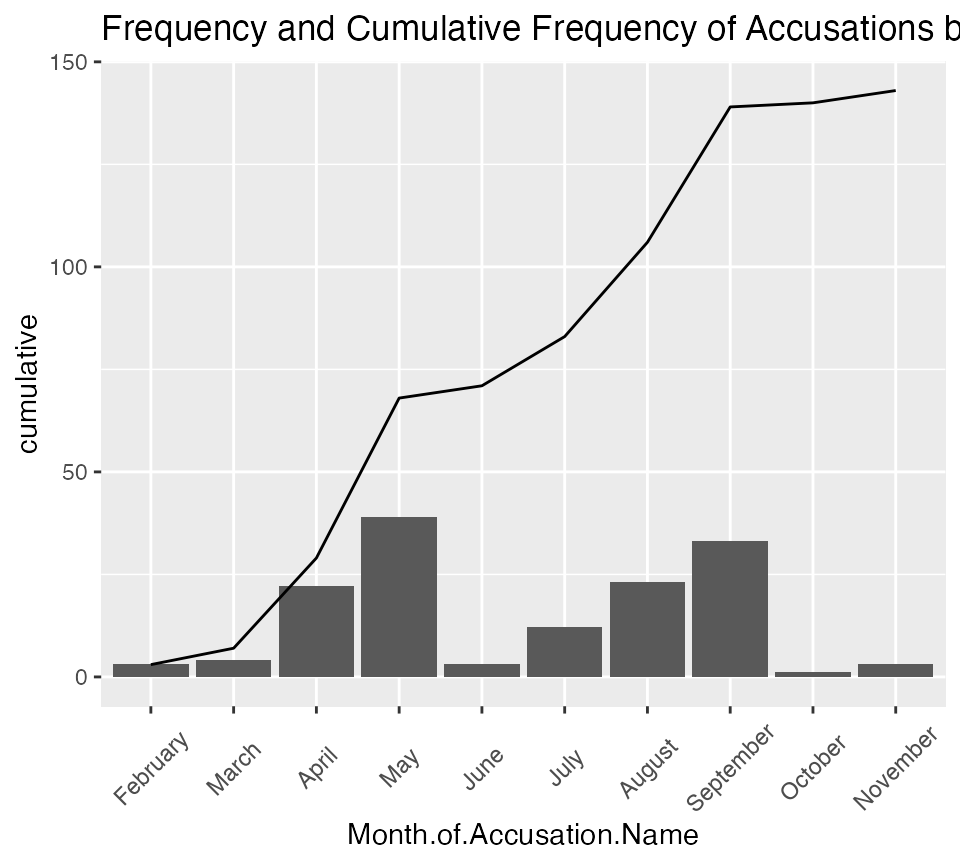
monthly_accusations |>
arrange(desc(number)) |>
mutate(Month.of.Accusation.Name =
factor(Month.of.Accusation.Name,
levels=Month.of.Accusation.Name)) |>
mutate(pareto_cumulative = cumsum(number) ) |>
ggplot() +
aes(x = Month.of.Accusation.Name, y = number) +
geom_col() +
labs(title = "Pareto Histogram of Accusations by Month") +
salem_theme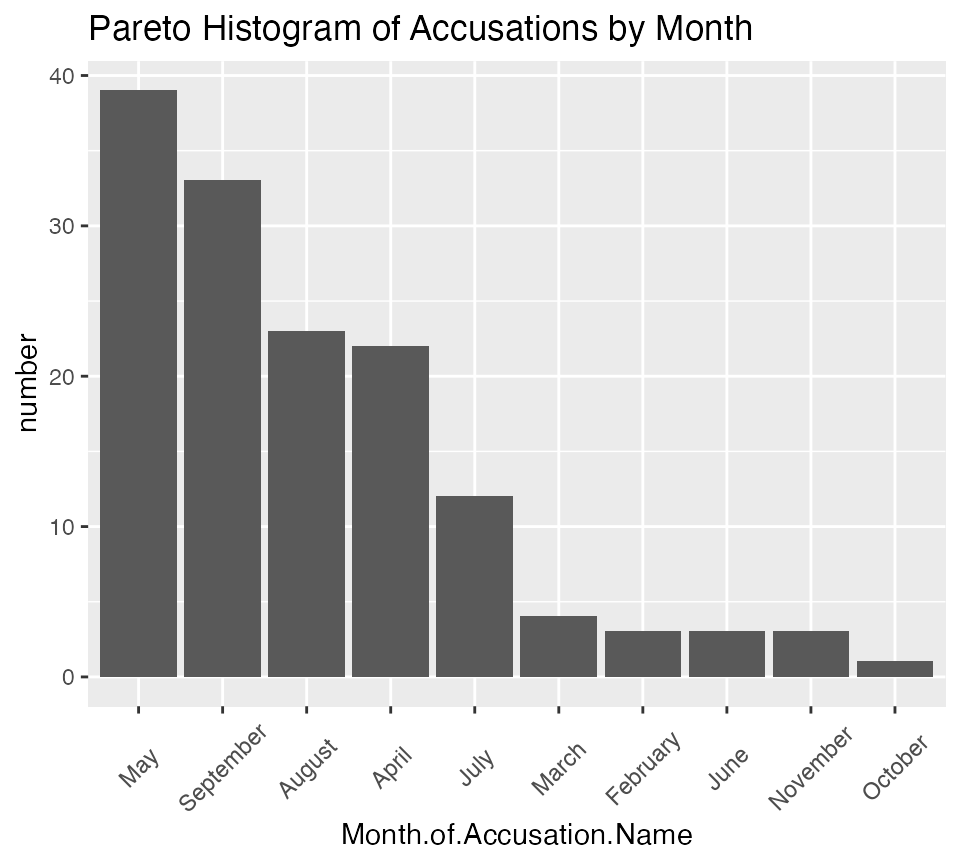
monthly_accusations |>
arrange(desc(number)) |>
mutate(Month.of.Accusation.Name =
factor(Month.of.Accusation.Name,
levels=Month.of.Accusation.Name)) |>
mutate(pareto_cumulative = cumsum(number) ) |>
ggplot() +
aes(x = Month.of.Accusation.Name, y = pareto_cumulative) +
geom_point( ) +
geom_path(aes(y=pareto_cumulative, group=1), colour="blue", lty=3,
linewidth= 0.9) +
labs(title = "Pareto Cumulative Distribution of Accusations by Month") +
salem_theme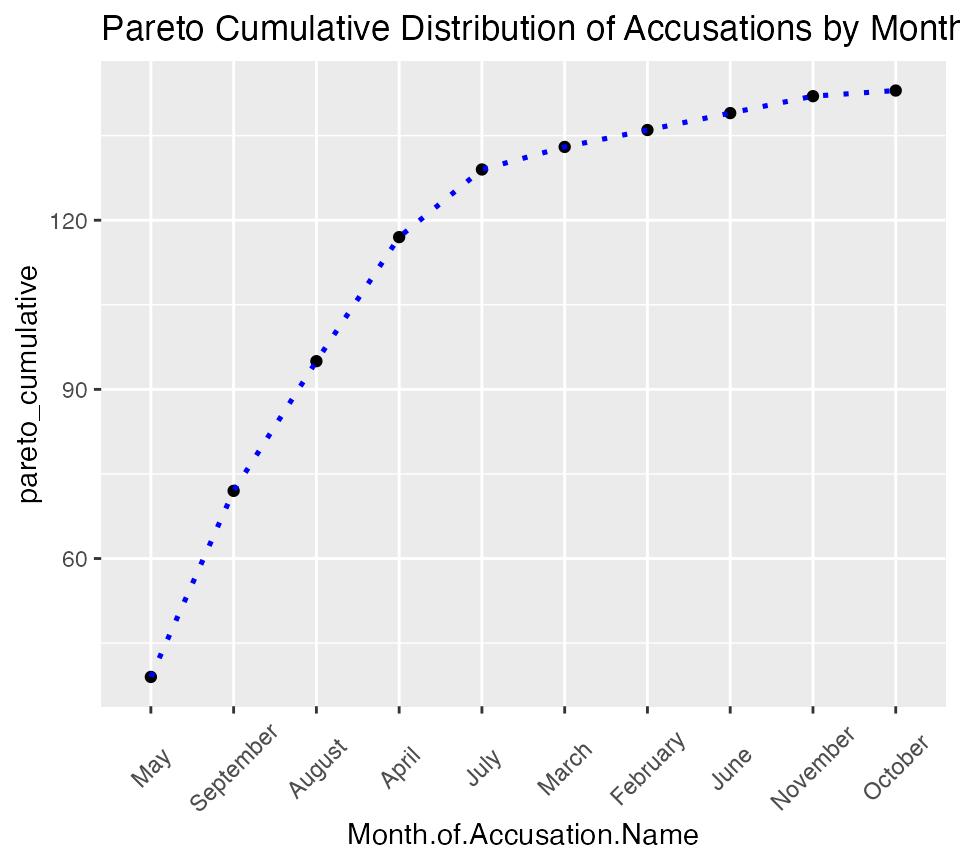
monthly_accusations |>
arrange(desc(number)) |>
mutate(Month.of.Accusation.Name =
factor(Month.of.Accusation.Name,
levels = Month.of.Accusation.Name)) |>
mutate(pareto_cumulative = cumsum(number) ) |>
ggplot() +
aes(x = Month.of.Accusation.Name, y = number) +
geom_col() +
geom_path(aes(y=pareto_cumulative, group = 1), colour = "blue",
lty = 3, linewidth = 0.9) +
labs(title = "Pareto Histogram of Accusations by Month") +
salem_theme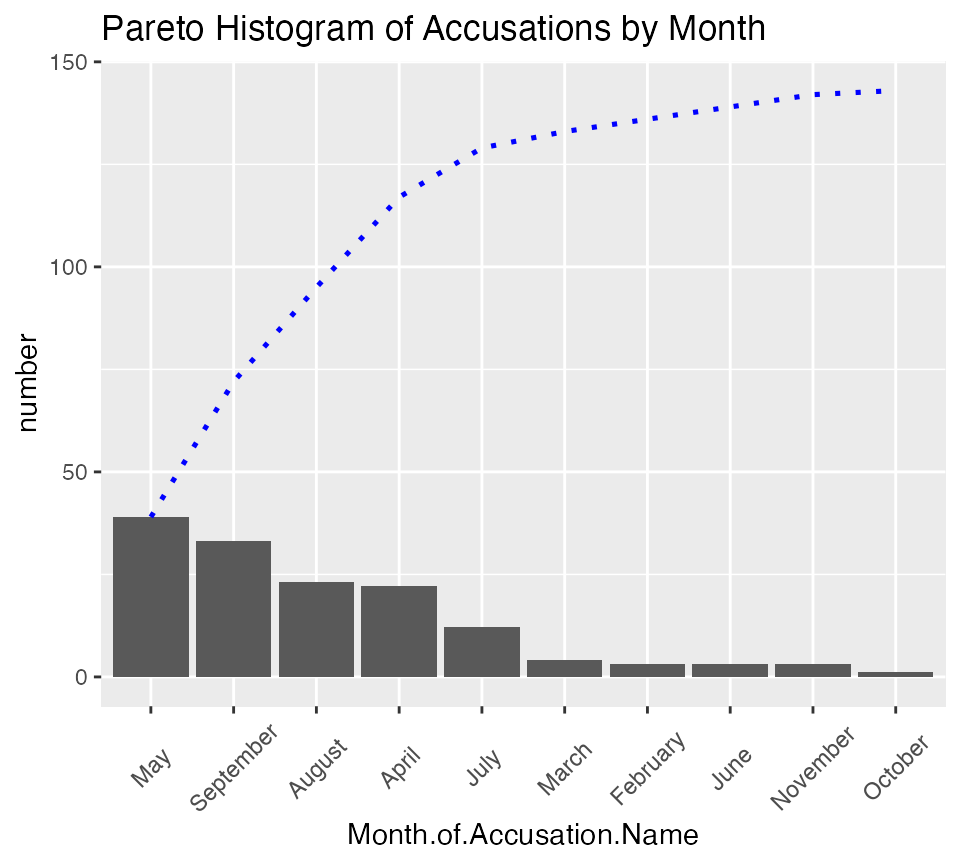
Executions
Creating the bar chart of executions over time is similar to creating that for accusations. Additionally, these are shown as what is termed scatterplots but now would be called line graphs.
Since most accused were not executed (and this is indicated by setting them to NA or missing) we’ll remove the missing cases from the graph.
ggplot(data = na.omit(accused_witches)) +
aes(x = Month.of.Execution.Name) +
geom_bar() +
labs(title = "Executions by month", x = "Month") +
scale_x_discrete(drop = FALSE) +
salem_theme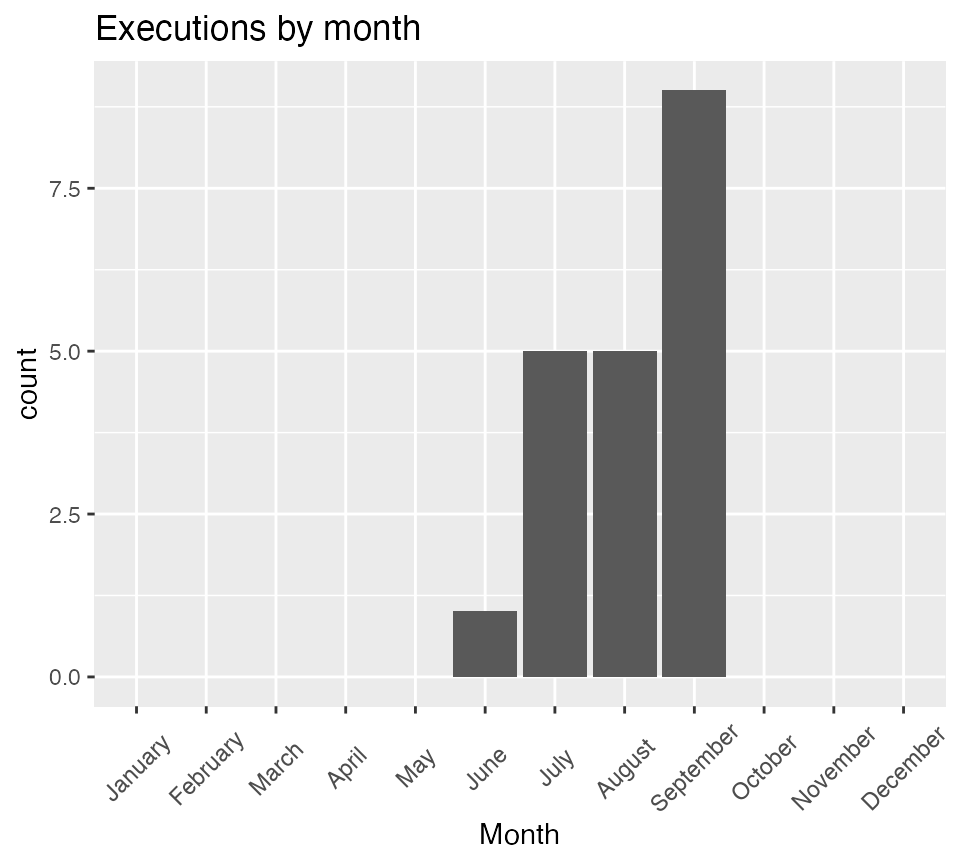
table(accused_witches$Month.of.Execution.Name, useNA = "ifany",
dnn = "Month") |> kable(caption = "Executions by Month")| Month | Freq |
|---|---|
| January | 0 |
| February | 0 |
| March | 0 |
| April | 0 |
| May | 0 |
| June | 1 |
| July | 5 |
| August | 5 |
| September | 9 |
| October | 0 |
| November | 0 |
| December | 0 |
| NA | 132 |
There are many ways to explore the relationship between executions and accusations. On the website this is displayed using overlapping line plots of the number of executions in a month and the number of accusations. If teaching, it is important to point out that the execuations in a month were not generally of the same people who were accused in that month. To reproduce this, one approach is to again use summarize() to create a monthly data set.
monthly_accused <- accused_witches |>
filter(!is.na(Month.of.Accusation)) |>
group_by(Month.of.Accusation.Name) |>
summarize(accusations = n()) |>
rename(Month = Month.of.Accusation.Name)
monthly_executed <- accused_witches |>
filter(!is.na(Month.of.Execution)) |>
group_by(Month.of.Execution.Name) |>
summarize(executions = n()) |>
rename(Month = Month.of.Execution.Name)
monthly_data <- left_join(monthly_accused, monthly_executed) |>
mutate(executions =
ifelse(is.na(executions), 0, executions))
ggplot(monthly_data) +
aes(x = Month, y = accusations, group = 1) +
geom_path( color = "blue" ) +
geom_line(aes(y = executions, x = Month, group = 1), color = "red") +
labs(title = "Executions and Accusations by Month",
subtitle = "Accusations in blue and executions in red") +
salem_theme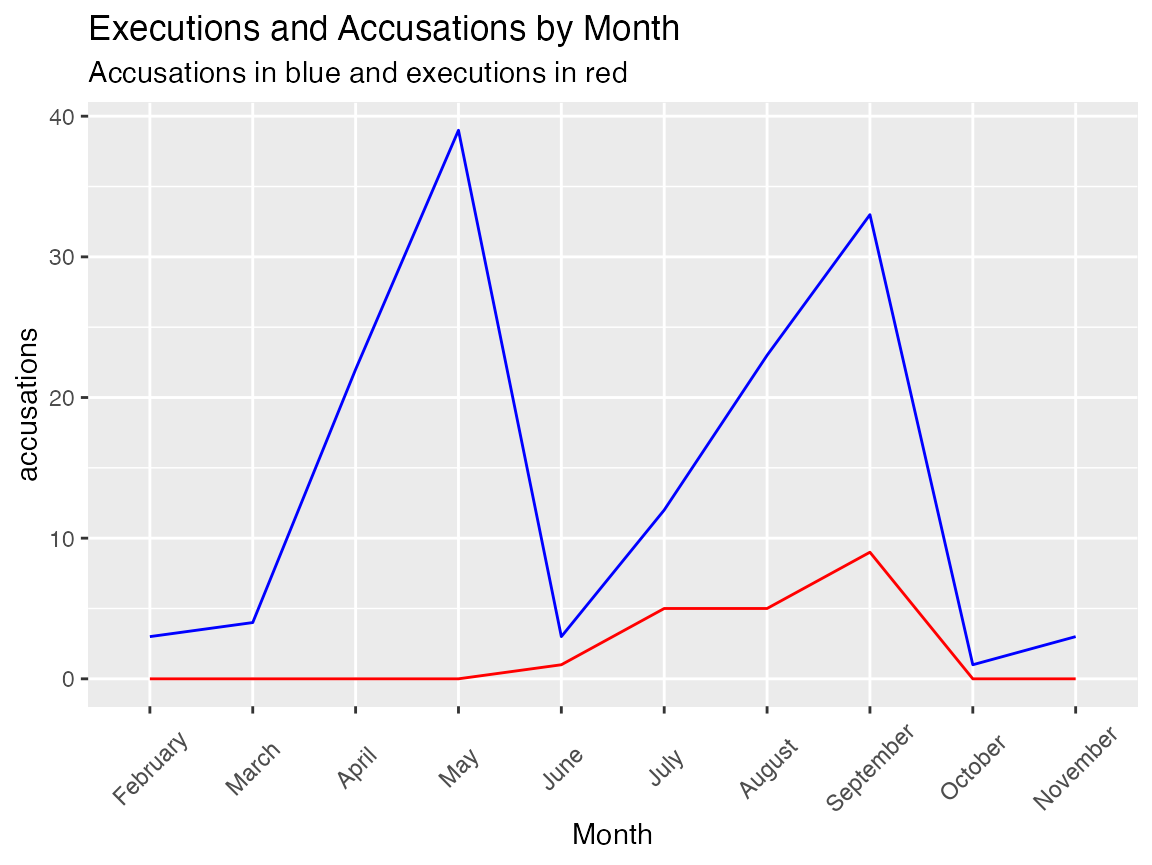
Geographic Spread of Accusations
The pivot table of month of accusation by town. However that table is huge and only the first seven columns are shown on the website. A more compact display is given below rather than using kable(). Also note that the row and column totals are added.
addmargins(table( accused_witches$Month.of.Accusation.Name, accused_witches$Residence,
dnn = c("Month", "Residence") ))
#> Residence
#> Month Amesbury Andover Beverly Billerica Boston Boxford Charlestown
#> January 0 0 0 0 0 0 0
#> February 0 0 0 0 0 0 0
#> March 0 0 0 0 0 0 0
#> April 1 0 2 0 0 0 0
#> May 0 1 1 3 2 0 2
#> June 0 0 1 0 0 0 0
#> July 0 6 0 0 0 0 0
#> August 0 12 0 0 0 3 0
#> September 0 23 0 0 0 0 0
#> October 0 0 0 0 0 0 0
#> November 0 0 0 0 0 0 0
#> December 0 0 0 0 0 0 0
#> Sum 1 42 4 3 2 3 2
#> Residence
#> Month Chelmsford Gloucester Haverhill Ipswich Lynn Malden Manchester
#> January 0 0 0 0 0 0 0
#> February 0 0 0 0 0 0 0
#> March 0 0 0 1 0 0 0
#> April 0 0 0 0 0 0 0
#> May 0 0 0 2 3 1 0
#> June 0 0 0 0 1 0 0
#> July 0 0 3 0 0 0 0
#> August 0 0 3 0 0 0 0
#> September 0 3 0 0 0 0 1
#> October 0 0 0 0 1 0 0
#> November 0 3 0 0 0 0 0
#> December 0 0 0 0 0 0 0
#> Sum 0 6 6 3 5 1 1
#> Residence
#> Month Marblehead Piscataqua, Maine Reading Rowley Salem Town
#> January 0 0 0 0 0
#> February 0 0 0 0 0
#> March 0 0 0 0 1
#> April 0 0 1 0 7
#> May 1 0 3 0 11
#> June 0 0 0 0 1
#> July 0 0 0 0 2
#> August 0 0 0 5 0
#> September 0 1 3 0 2
#> October 0 0 0 0 0
#> November 0 0 0 0 0
#> December 0 0 0 0 0
#> Sum 1 1 7 5 24
#> Residence
#> Month Salem Village Salisbury Topsfield Wells, Maine Woburn Sum
#> January 0 0 0 0 0 0
#> February 3 0 0 0 0 3
#> March 2 0 0 0 0 4
#> April 4 0 6 1 0 22
#> May 6 0 0 0 3 39
#> June 0 0 0 0 0 3
#> July 0 1 0 0 0 12
#> August 0 0 0 0 0 23
#> September 0 0 0 0 0 33
#> October 0 0 0 0 0 1
#> November 0 0 0 0 0 3
#> December 0 0 0 0 0 0
#> Sum 15 1 6 1 3 143The site discusses the “grand total” data (the row sum) as reflecting the varying intensity in the different towns. This can also be shown using a univariate table (or dplyr::summarize())
| Residence | Freq |
|---|---|
| Amesbury | 1 |
| Andover | 45 |
| Beverly | 4 |
| Billerica | 3 |
| Boston | 2 |
| Boxford | 3 |
| Charlestown | 2 |
| Chelmsford | 1 |
| Gloucester | 9 |
| Haverhill | 6 |
| Ipswich | 4 |
| Lynn | 5 |
| Malden | 1 |
| Manchester | 1 |
| Marblehead | 1 |
| Piscataqua, Maine | 2 |
| Reading | 7 |
| Rowley | 5 |
| Salem Town | 24 |
| Salem Village | 15 |
| Salisbury | 1 |
| Topsfield | 6 |
| Wells, Maine | 1 |
| Woburn | 3 |
accused_witches |> group_by(Residence) |> summarize(number = n()) |>
kable(caption = "Residences of Accused")| Residence | number |
|---|---|
| Amesbury | 1 |
| Andover | 45 |
| Beverly | 4 |
| Billerica | 3 |
| Boston | 2 |
| Boxford | 3 |
| Charlestown | 2 |
| Chelmsford | 1 |
| Gloucester | 9 |
| Haverhill | 6 |
| Ipswich | 4 |
| Lynn | 5 |
| Malden | 1 |
| Manchester | 1 |
| Marblehead | 1 |
| Piscataqua, Maine | 2 |
| Reading | 7 |
| Rowley | 5 |
| Salem Town | 24 |
| Salem Village | 15 |
| Salisbury | 1 |
| Topsfield | 6 |
| Wells, Maine | 1 |
| Woburn | 3 |
The website contains a towns data set that essentially reproduces the large contingency table. This makes sense to do in Excel, but in R we do not need to makea separate data set.
To make a histogram for each town we can select the town we want. This is illustrated below for Andover.
Note that in the data set the white space from the beginning and ending of the place names has been removed.
accused_witches |> filter(Residence == "Andover") |>
ggplot() +
aes(x = Month.of.Accusation.Name) +
geom_bar() +
scale_x_discrete(drop=FALSE) +
salem_theme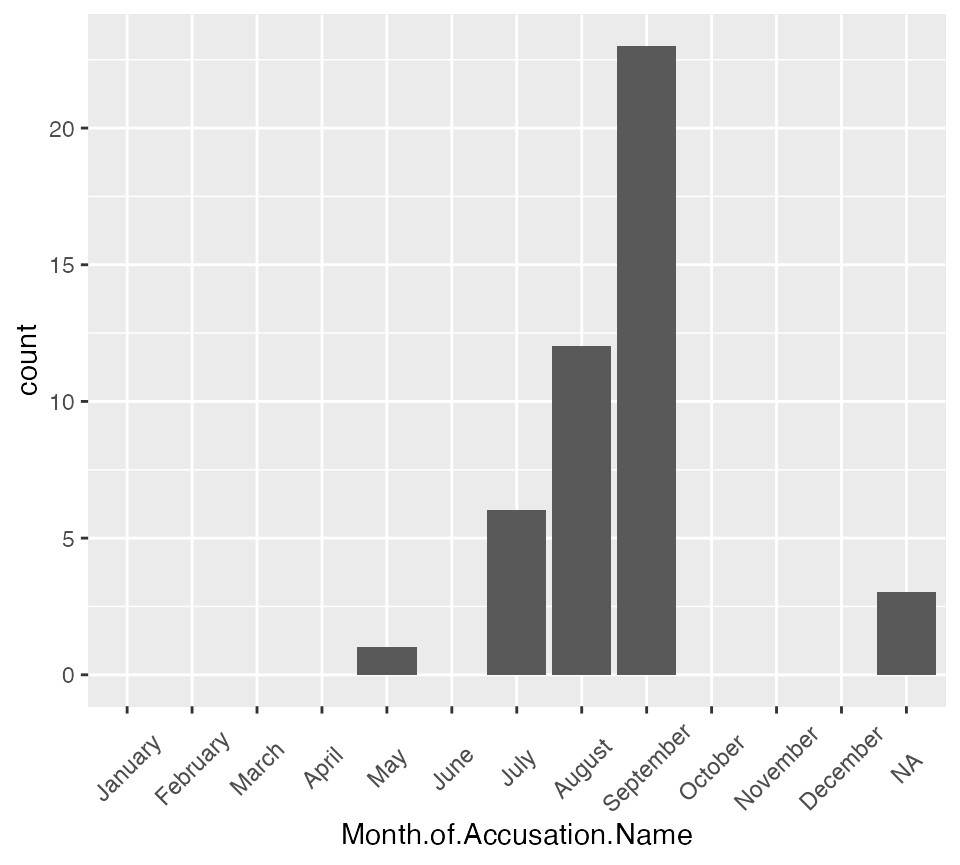
The website encourages examining the period before and after the
convening of the Court of Oyer and Terminer in June.
To help make this more visible we can add a vline.
accused_witches |> filter(Residence == "Andover") |>
ggplot() +
aes(x = Month.of.Accusation.Name) +
geom_bar() +
geom_vline(xintercept = 6.5, color = "red") +
scale_x_discrete(drop = FALSE) +
labs(title = "Accusations by Month",
subtitle = "Red line indicates reconvening of the Court of Oyer and Terminer",
x = "Month of accusation") +
salem_theme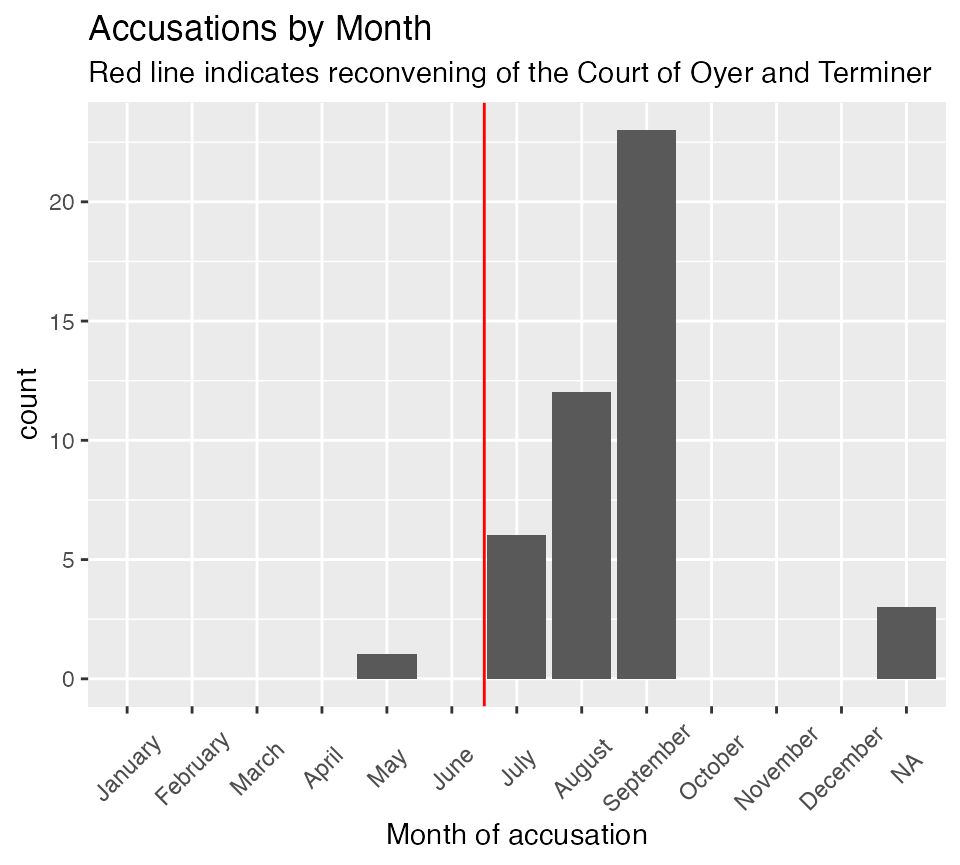
Alternatively, we can use faceting to show all of the histograms.
accused_witches |>
ggplot() +
aes(x = Month.of.Accusation.Name) +
geom_bar() +
geom_vline(xintercept = 6.5, color = "red") +
scale_x_discrete(drop = FALSE) +
facet_wrap(facets = vars(Residence), ncol = 4) +
labs(title = "Number of accusations by month",
subtitle = "Red line indicates reconvening of the Court of Oyer and Terminer",
x = "Month of Accusation") +
theme(axis.text.x = element_text(angle = 90, vjust = .5))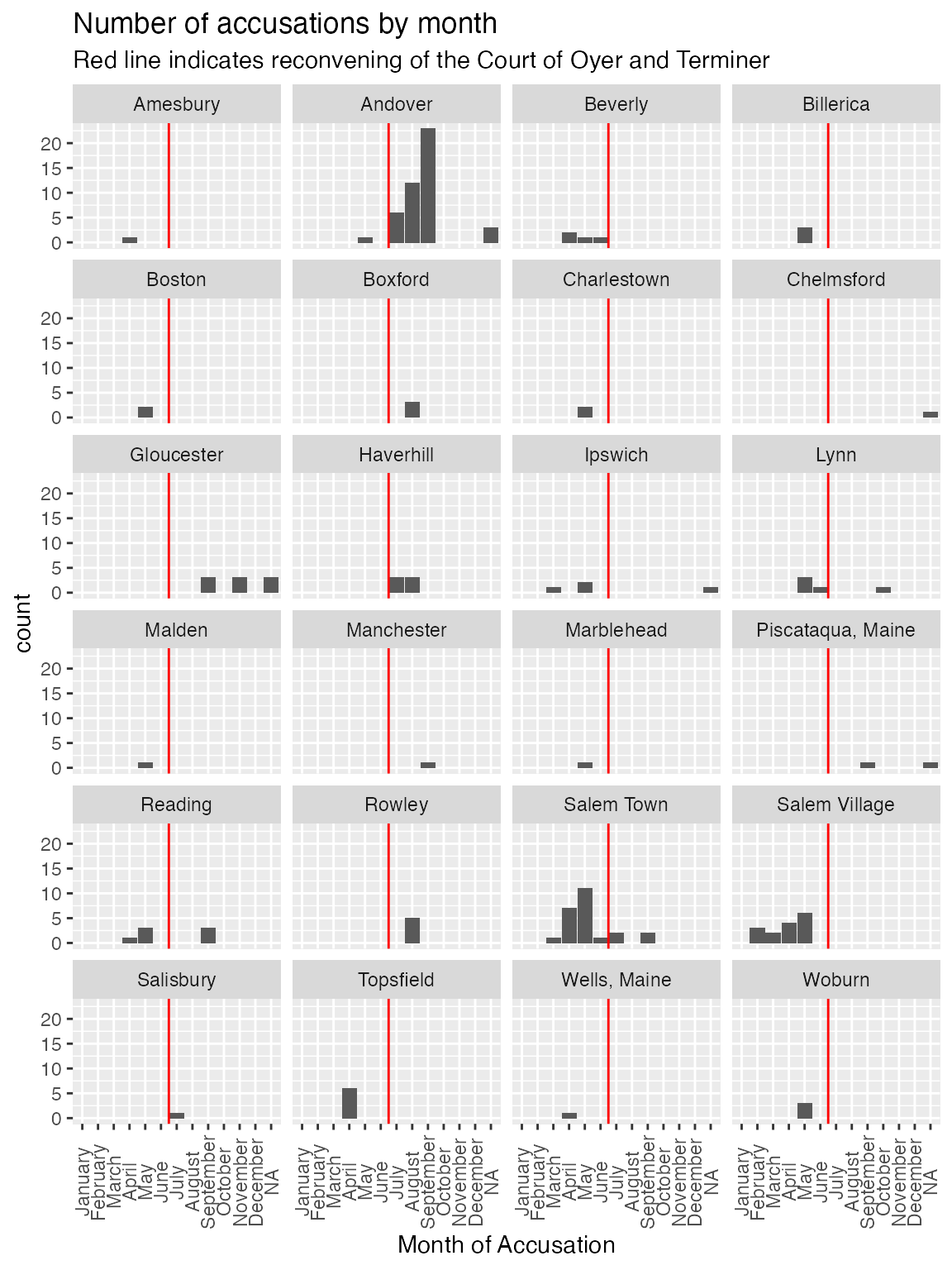
Maps
We can use maps to represent the geographic distribution over time spatially. The salem_region data set is an sf (simple features) data set that provides geographic data for the towns in the three Massachuessets counties represented in our data: Essex, Middlesex and Sussex.
To use this data you will need to install the sf package. The code at the start of the second code chunk tests for whether you have done this.
Not all of the towns in these three counties had accusations: the majority did not. The data also include the total accused for each town and the monthly accused for the towns that ever had an accusation. However, these variables should never be used outside of maps because the results will be incorrect. This is because many towns have multiple records. This is especially true if they include islands, which is common in this region of the state. These are based on modern municipal boundaries which are close to but not the same as the historical ones. There are many geographic analyses that can be done. Below a comparison of the distribution of whether towns had at least on accusation in each of four months is given.
First, create variables indicating whether towns did or did not have an accusation in a month and remove the TOWN_LABELs for all the towns that never had an accusation.
newdata <- salem_region |> mutate(February.Any = February > 0, March.Any = March > 0,
April.Any = April > 0, May.Any = May > 0,
June.Any = June > 0, July.Any = July > 0,
August.Any = August > 0,
September.Any = September >0,
October.Any = October > 0,
November.Any = November > 0)
newdata$TOWN_LABEL <- ifelse(newdata$n_accused == 0, NA, newdata$TOWN_LABEL)Here requireNamespace is used to check whether the
sf package is installed. That is because sf is
only suggested and not required. It can be complex to install on some
computers.
if (requireNamespace("sf", quietly = TRUE)) {
library(sf)
p1 <- ggplot(newdata)
p2 <- geom_sf_text(aes(label = TOWN_LABEL), color = "blue", size = 2,
nudge_x = 5,
nudge_y = 5, na.rm = TRUE)
p3 <- scale_fill_manual(values = c( "grey", "red"), na.value = "white")
}
if (requireNamespace("sf", quietly = TRUE)) {
p1 + geom_sf(data = newdata,
aes(geometry = newdata$geometry, fill = February.Any
), color = "black",
size = .1) +
p3 + p2 + labs(title = "Location of Accusations in February")
}
if (requireNamespace("sf", quietly = TRUE)) {
library(sf)
p1 + geom_sf(data = newdata,
aes(geometry = geometry, fill = July.Any),
color = "black", size = .1) +
p3 + p2 + labs(title = "Location of Accusations in July")
}
if (requireNamespace("sf", quietly = TRUE)) {
p1 + geom_sf(data = newdata,
aes(fill = August.Any, geometry = geometry), color = "black",
size = .1) +
p3 + p2 + labs(title = "Location of Accusations in August")
}
if (requireNamespace("sf", quietly = TRUE)) {
p1 + geom_sf(data = newdata, aes(fill = November.Any, geometry = geometry), color = "black",
size = .1) +
p3 + p2 + labs(title = "Location of Accusations in November")
}Social Conflict
The website explores a variety of dimensions of social conflict in the Salem region. One of the important social cleavages was between those who did or did not support Reverend Parris, who had been appointed as the minister for the new church in Salem Village. (This was the Puritan church, which was the official church in Massacheusetts.)
The site has two data sets, one of pro-Parris individuals and one of
anti-Parris individuals. For use in R these have been combined with an
added variable identifying the position of the indivual. This data set
is called parris_social. Also the original column label for the
anti-Parris data was “[Church] Member” while for the pro-Parris data it
was “Church-Member.” In the parris_social data Church-Member is used.
Using the variable view it can be subset to pro- and anti-
groups. However it is not necessary to do this.
A three-way table can be created, as one example. Two ways of doing this are shown. Marginals and proportions could be added.
table(parris_social$Sex, parris_social$Identification, parris_social$view,
dnn = c("Sex", "Identification", "View"))
#> , , View = Anti-Parris
#>
#> Identification
#> Sex Church-Member Free-Holder Householder Non-Member Young men. 16 years old
#> F 11 0 0 16 0
#> M 6 5 29 0 17
#>
#> , , View = Pro-Parris
#>
#> Identification
#> Sex Church-Member Free-Holder Householder Non-Member Young men. 16 years old
#> F 27 0 24 0 0
#> M 25 0 29 0 0
ftable(parris_social$Sex, parris_social$Identification, parris_social$view,
dnn = c("Sex", "Identification", "View"))
#> View Anti-Parris Pro-Parris
#> Sex Identification
#> F Church-Member 11 27
#> Free-Holder 0 0
#> Householder 0 24
#> Non-Member 16 0
#> Young men. 16 years old 0 0
#> M Church-Member 6 25
#> Free-Holder 5 0
#> Householder 29 29
#> Non-Member 0 0
#> Young men. 16 years old 17 0Treating position on Parris as the dependent varable, we might rearrange the tables.
table(parris_social$view, parris_social$Identification, parris_social$Sex,
dnn = c("View", "Identification", "Sex"))
#> , , Sex = F
#>
#> Identification
#> View Church-Member Free-Holder Householder Non-Member
#> Anti-Parris 11 0 0 16
#> Pro-Parris 27 0 24 0
#> Identification
#> View Young men. 16 years old
#> Anti-Parris 0
#> Pro-Parris 0
#>
#> , , Sex = M
#>
#> Identification
#> View Church-Member Free-Holder Householder Non-Member
#> Anti-Parris 6 5 29 0
#> Pro-Parris 25 0 29 0
#> Identification
#> View Young men. 16 years old
#> Anti-Parris 17
#> Pro-Parris 0
ftable( parris_social$Identification, parris_social$view, parris_social$Sex,
dnn = c("View", "Identification", "Sex"))
#> Sex F M
#> View Identification
#> Church-Member Anti-Parris 11 6
#> Pro-Parris 27 25
#> Free-Holder Anti-Parris 0 5
#> Pro-Parris 0 0
#> Householder Anti-Parris 0 29
#> Pro-Parris 24 29
#> Non-Member Anti-Parris 16 0
#> Pro-Parris 0 0
#> Young men. 16 years old Anti-Parris 0 17
#> Pro-Parris 0 0The parris_social data set focuses on those who signed pro- and anti-Parris petitions. In contrast, the salem_village data set includes individuals who did not sign petitions in addition to those who did. However, it is limited to those who paid taxes so many of the young men and women of all ages who are in the parris_social data are not included. This also includes data from multiple years.
The basic table for this is the analysis of church membership and position on Parris.
table(salem_village$Petition, salem_village$Church.to.1696,
dnn = c( "Membership", "View"))
#> View
#> Membership Church Non-Church
#> Anti-P 8 32
#> NoS 1 43
#> Pro-P 25 28
addmargins( table(salem_village$Petition, salem_village$Church.to.1696,
dnn = c( "Membership", "View")))
#> View
#> Membership Church Non-Church Sum
#> Anti-P 8 32 40
#> NoS 1 43 44
#> Pro-P 25 28 53
#> Sum 34 103 137Political Power
As explained on the website, the Village of Salem was governed by a Committee of Five in addition to the Town Meeting see Salem Village Politics.
The data set that is part of this package called committee_list is structured differently than the original data. It is in “long” format with one row per person-year for each committee member for the years they served. This can be coverted to various other formats if desired.
You can make a table see how the make up of the committee changed over the period from 1687 to 1698.
table(committee_list$Petition, committee_list$Year, dnn = c("Petition", "Year"))
#> Year
#> Petition 1685 1686 1687 1688 1689 1690 1691 1692 1693 1694 1695 1696 1697 1698
#> Anti-P 1 1 2 2 2 2 5 4 4 0 0 0 2 2
#> NoS 1 1 0 0 0 0 0 0 1 0 1 0 0 0
#> Pro-P 3 3 3 2 3 3 0 1 0 5 4 5 3 3The website shows a complex pivot table involving three variables.
table( committee_list$Petition, committee_list$Social, committee_list$Year )
#> , , = 1685
#>
#>
#> Church Member Freeholder Householder
#> Anti-P 0 0 1
#> NoS 0 0 1
#> Pro-P 2 0 1
#>
#> , , = 1686
#>
#>
#> Church Member Freeholder Householder
#> Anti-P 1 0 0
#> NoS 0 0 1
#> Pro-P 3 0 0
#>
#> , , = 1687
#>
#>
#> Church Member Freeholder Householder
#> Anti-P 1 1 0
#> NoS 0 0 0
#> Pro-P 3 0 0
#>
#> , , = 1688
#>
#>
#> Church Member Freeholder Householder
#> Anti-P 0 0 2
#> NoS 0 0 0
#> Pro-P 2 0 0
#>
#> , , = 1689
#>
#>
#> Church Member Freeholder Householder
#> Anti-P 1 0 1
#> NoS 0 0 0
#> Pro-P 3 0 0
#>
#> , , = 1690
#>
#>
#> Church Member Freeholder Householder
#> Anti-P 1 0 1
#> NoS 0 0 0
#> Pro-P 3 0 0
#>
#> , , = 1691
#>
#>
#> Church Member Freeholder Householder
#> Anti-P 0 0 5
#> NoS 0 0 0
#> Pro-P 0 0 0
#>
#> , , = 1692
#>
#>
#> Church Member Freeholder Householder
#> Anti-P 1 0 3
#> NoS 0 0 0
#> Pro-P 1 0 0
#>
#> , , = 1693
#>
#>
#> Church Member Freeholder Householder
#> Anti-P 1 0 3
#> NoS 0 0 1
#> Pro-P 0 0 0
#>
#> , , = 1694
#>
#>
#> Church Member Freeholder Householder
#> Anti-P 0 0 0
#> NoS 0 0 0
#> Pro-P 5 0 0
#>
#> , , = 1695
#>
#>
#> Church Member Freeholder Householder
#> Anti-P 0 0 0
#> NoS 0 0 1
#> Pro-P 4 0 0
#>
#> , , = 1696
#>
#>
#> Church Member Freeholder Householder
#> Anti-P 0 0 0
#> NoS 0 0 0
#> Pro-P 3 0 2
#>
#> , , = 1697
#>
#>
#> Church Member Freeholder Householder
#> Anti-P 1 0 1
#> NoS 0 0 0
#> Pro-P 3 0 0
#>
#> , , = 1698
#>
#>
#> Church Member Freeholder Householder
#> Anti-P 0 0 2
#> NoS 0 0 0
#> Pro-P 3 0 0One way to explore the association is to cross tabulate the Petition and Social variables. However, this counts the same people multiple times if they served for multiple years.
table( committee_list$Petition, committee_list$Social )
#>
#> Church Member Freeholder Householder
#> Anti-P 7 1 19
#> NoS 0 0 4
#> Pro-P 35 0 3To adjust for this and get the data matching the website we need to remove those duplicates. Then the table matches that found at Committee Social Report.
committee_list2 <- committee_list |> group_by(Committee.Members) |>
summarize(Social = first(Social),
Petition = first(Petition),
Terms = n())
addmargins(table( committee_list2$Petition, committee_list2$Social ))
#>
#> Church Member Freeholder Householder Sum
#> Anti-P 4 1 10 15
#> NoS 0 0 3 3
#> Pro-P 10 0 3 13
#> Sum 14 1 16 31Wealth and Salem Village Conflict
The tax_comparison data set is also set up in long format. This can then be used to create a comparison table similar to the table on Tax Comparison. One limitation is that R does not have a built in function for the mode.
This is the most complex analysis on the website. Complications include people moving in and out of the data in different years (individuals appear between one and six times), the changing amount of taxes over the time period and name changes. The analysis looks at both group and individual level comparisons and individual level mobility.
Here is the distribution of tax payers by year.
| Year | Freq |
|---|---|
| 1681 | 94 |
| 1690 | 100 |
| 1694 | 105 |
| 1695 | 105 |
| 1697 | 100 |
| 1700 | 114 |
The next table summarizes descriptive statistics for all of the
years. The website general shows one year at a time or in some cases
compares two years. You can add filter(Year = 1681) to
display only the 1681 data, changing the filter to select whatever years
you want. For example to select all of the data for 1681 through 1694
one way would be to add
select(Year >= 1691 & Year <= 1694).
Let’s start by looking at the group level data.
The first table is for everyone in a year. The second separates the data based on which petition the tax payer signed (or if they) did not sign.
tax_comparison |> group_by(Year) |>
summarize(mean = round(mean(Tax), 1), median = round(median(Tax), 1),
minimum = min(Tax),
maximum = max(Tax), range = maximum - minimum,
sum = sum(Tax), Count = n()) |>
kable(caption = "Taxes paid by year")| Year | mean | median | minimum | maximum | range | sum | Count |
|---|---|---|---|---|---|---|---|
| 1681 | 42.5 | 30.0 | 2.25 | 206.25 | 204 | 3992.0 | 94 |
| 1690 | 13.2 | 8.0 | 2.00 | 50.00 | 48 | 1323.5 | 100 |
| 1694 | 11.7 | 9.0 | 3.00 | 52.00 | 49 | 1229.0 | 105 |
| 1695 | 11.6 | 8.0 | 3.00 | 58.00 | 55 | 1222.5 | 105 |
| 1697 | 16.1 | 12.0 | 3.00 | 75.00 | 72 | 1605.5 | 100 |
| 1700 | 12.5 | 9.5 | 3.00 | 46.00 | 43 | 1428.0 | 114 |
tax_comparison |> group_by(Year, Petition) |>
summarize(mean = round(mean(Tax), 1), median = round(median(Tax), 1),
minimum = min(Tax),
maximum = max(Tax), range = maximum - minimum,
sum = sum(Tax), Tax_payers = n()) |>
kable(caption = "Taxes paid by year and petition signed")| Year | Petition | mean | median | minimum | maximum | range | sum | Tax_payers |
|---|---|---|---|---|---|---|---|---|
| 1681 | Anti-P | 62.9 | 51.0 | 16.00 | 166.00 | 150.0 | 1509.25 | 24 |
| 1681 | NoS | 26.4 | 18.0 | 2.25 | 206.25 | 204.0 | 1268.25 | 48 |
| 1681 | Pro-P | 55.2 | 40.8 | 9.00 | 190.00 | 181.0 | 1214.50 | 22 |
| 1690 | Anti-P | 15.8 | 14.0 | 4.00 | 50.00 | 46.0 | 538.00 | 34 |
| 1690 | NoS | 8.0 | 5.5 | 2.00 | 30.00 | 28.0 | 224.50 | 28 |
| 1690 | Pro-P | 14.8 | 14.0 | 3.00 | 40.00 | 37.0 | 561.00 | 38 |
| 1694 | Anti-P | 14.4 | 10.5 | 4.50 | 52.00 | 47.5 | 531.00 | 37 |
| 1694 | NoS | 7.0 | 5.8 | 3.00 | 24.00 | 21.0 | 111.50 | 16 |
| 1694 | Pro-P | 11.3 | 9.0 | 3.50 | 38.00 | 34.5 | 586.50 | 52 |
| 1695 | Anti-P | 15.1 | 11.2 | 4.00 | 58.00 | 54.0 | 545.00 | 36 |
| 1695 | NoS | 6.6 | 6.0 | 3.00 | 24.00 | 21.0 | 111.50 | 17 |
| 1695 | Pro-P | 10.9 | 8.0 | 3.00 | 40.00 | 37.0 | 566.00 | 52 |
| 1697 | Anti-P | 19.0 | 13.5 | 3.00 | 75.00 | 72.0 | 722.50 | 38 |
| 1697 | NoS | 8.9 | 8.0 | 3.00 | 32.00 | 29.0 | 195.00 | 22 |
| 1697 | Pro-P | 17.2 | 14.5 | 5.00 | 54.00 | 49.0 | 688.00 | 40 |
| 1700 | Anti-P | 14.9 | 12.0 | 4.00 | 46.00 | 42.0 | 612.00 | 41 |
| 1700 | NoS | 7.3 | 5.0 | 3.00 | 26.00 | 23.0 | 254.50 | 35 |
| 1700 | Pro-P | 14.8 | 12.0 | 4.00 | 38.00 | 34.0 | 561.50 | 38 |
To do the analysis comparing the median tax paid for the three groups we can graph the values over time. In this case, we will first make a data set of statistics to work with.
yearly_tax <- tax_comparison |> group_by(Year, Petition) |>
summarize(mean = round(mean(Tax), 1), median = round(median(Tax), 1),
minimum = min(Tax),
maximum = max(Tax), range = maximum - minimum,
sum = sum(Tax), Count = n())
ggplot(yearly_tax) +
aes(x = Year, y = median, group = Petition, color = Petition) +
geom_line() +
labs(title = "Tax paid by petition", y = "Shillings", x = "Year") 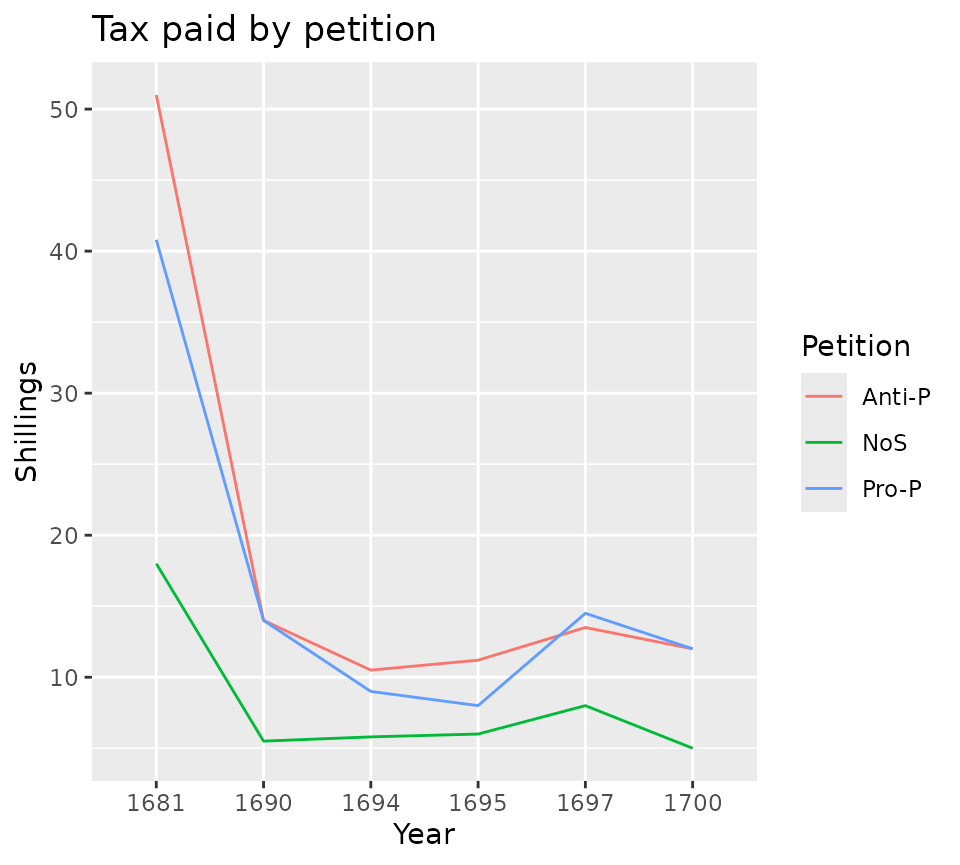
The analysis of annual data on the website specifically focuses on thse who were Pro- and Anti- Parris based on petition signatures. As can be seen in the previous graph, those who did not sign petititions always had a lower median tax, but the other two groups were inconsistent. To address this the site presents the ratio of the medians of the two group. A ratio of 1.0 means that the median tax for the two groups was identical. A ratio of great than 1 means that the Pro-Parris group had a higher median. A ratio of less than one means that the Anti-Parris group had a higher median.
ratios <- yearly_tax |> filter(Petition %in% c("Pro-P", "Anti-P")) |>
select(Year, Petition, median) |>
pivot_wider(id_cols = c(Year), values_from = median,
names_from = Petition) |>
mutate(median_ratio = `Pro-P`/`Anti-P`)
ratios |> kable()| Year | Anti-P | Pro-P | median_ratio |
|---|---|---|---|
| 1681 | 51.0 | 40.8 | 0.8000000 |
| 1690 | 14.0 | 14.0 | 1.0000000 |
| 1694 | 10.5 | 9.0 | 0.8571429 |
| 1695 | 11.2 | 8.0 | 0.7142857 |
| 1697 | 13.5 | 14.5 | 1.0740741 |
| 1700 | 12.0 | 12.0 | 1.0000000 |
ggplot(ratios,
aes(x = Year, y = median_ratio)) +
geom_point() +
geom_line(group = 1) +
geom_hline(yintercept = 1, color = "blue") +
labs(title = "Ratio of Pro- to Anti- Parris median tax",
y = "Ratio", x = "Year") 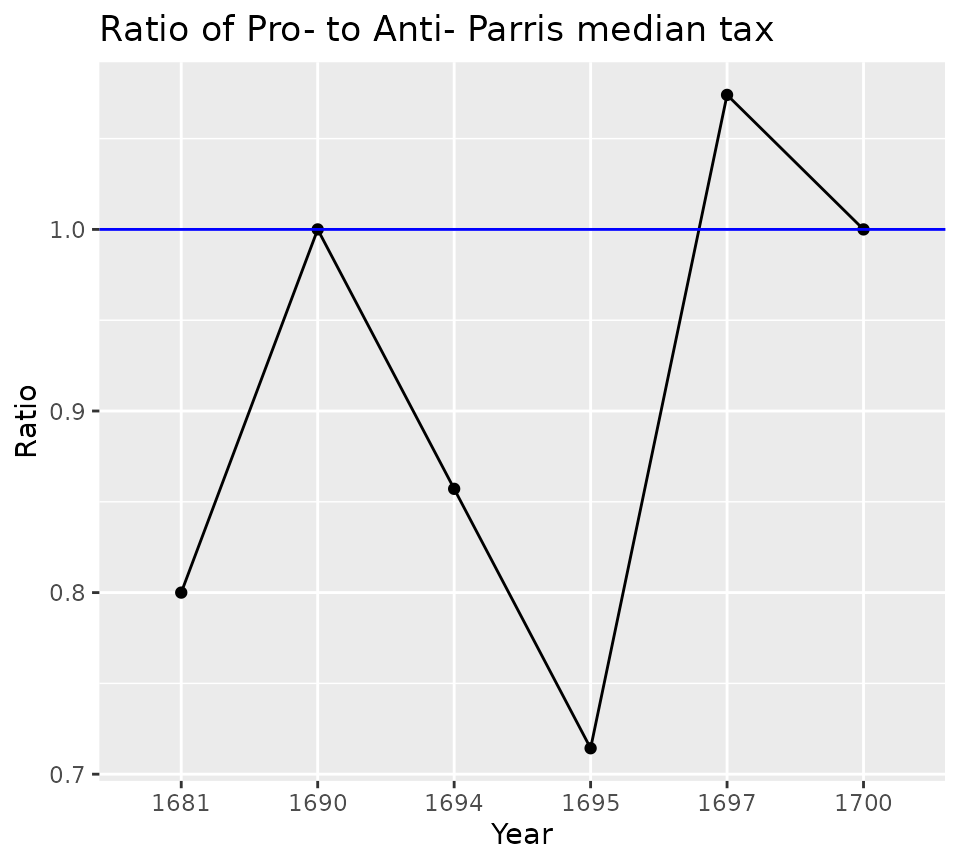
The same analysis can be done but substituting mean for median.
ratios <- yearly_tax |> filter(Petition %in% c("Pro-P", "Anti-P")) |>
select(Year, Petition, mean) |>
pivot_wider(id_cols = c(Year), values_from = mean,
names_from = Petition) |>
mutate(mean_ratio = `Pro-P`/`Anti-P`)
ratios |> kable()| Year | Anti-P | Pro-P | mean_ratio |
|---|---|---|---|
| 1681 | 62.9 | 55.2 | 0.8775835 |
| 1690 | 15.8 | 14.8 | 0.9367089 |
| 1694 | 14.4 | 11.3 | 0.7847222 |
| 1695 | 15.1 | 10.9 | 0.7218543 |
| 1697 | 19.0 | 17.2 | 0.9052632 |
| 1700 | 14.9 | 14.8 | 0.9932886 |
ggplot(ratios,
aes(x = Year, y = mean_ratio)) +
geom_point() +
geom_line(group = 1) +
geom_hline(yintercept = 1, color = "blue") +
labs(title = "Ratio of Pro- to Anti- Parris mean tax",
y = "Ratio", x = "Year") 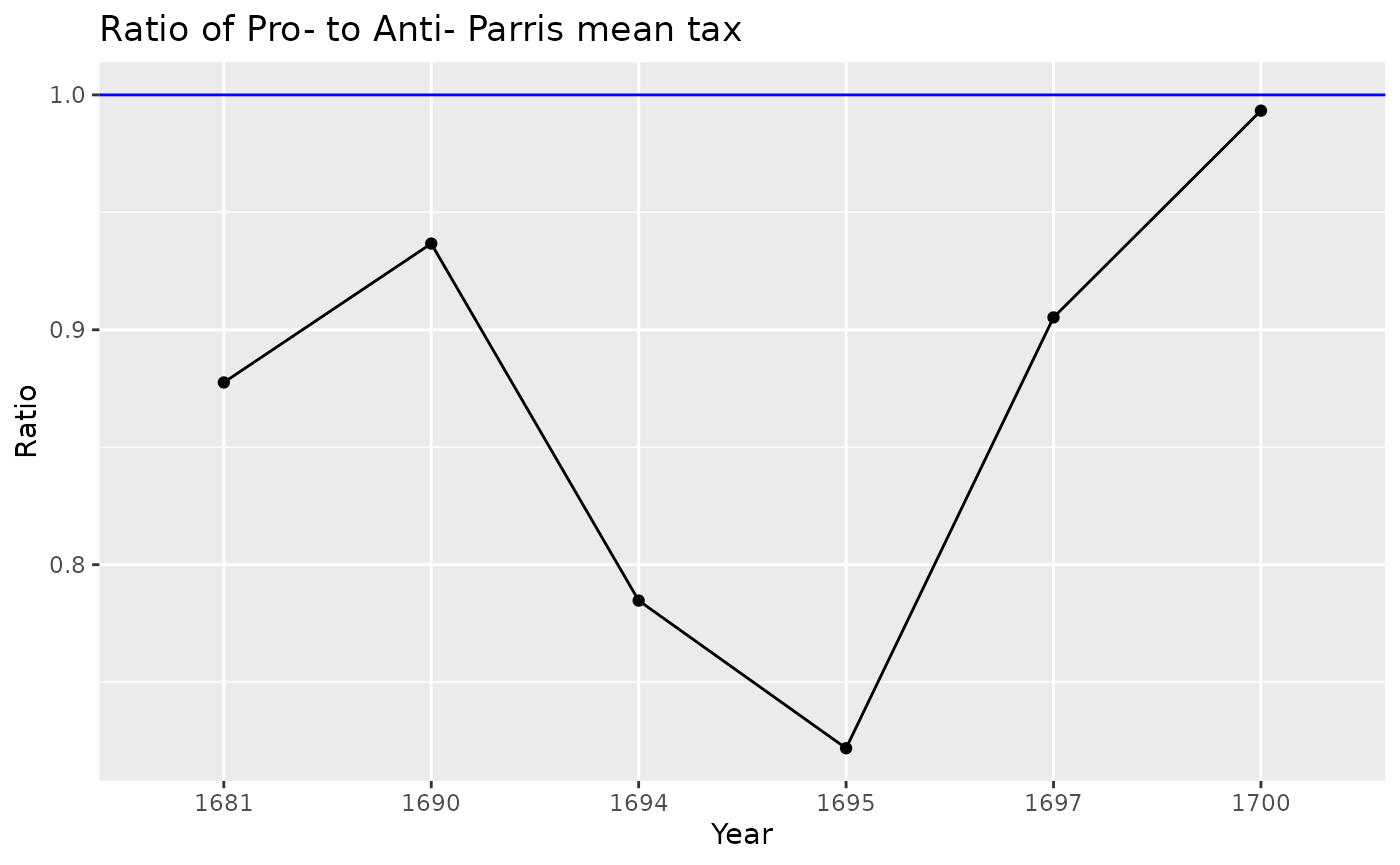
The site also looks at individual trajectories using ranks and percentiles within each year, allowing analysis of whether an individual’s financial position changed substantially over time. Individuals whose percentile changed by more than 10 are considered to have moved substantially.
There are many ways to do this, and the method chosen will depend on your purposes. The example below is not necessarily the best or most efficient. To do the analysis we need to obtain the rank and percentile for each of the tax amounts within the years. Finally, we need to compare those. In this example we will focus on the 1681-1690 comparison shown while providing a framework for the others.
First create a wide data set and calculate ranks and cumulative proportions. This allows viewing and sorting of individuals for specific years.
persisters <- tax_comparison |> pivot_wider(id_cols = c(Name, Petition),
names_from = Year,
names_prefix = "X",
values_from = Tax
) |>
relocate(X1681, .before = X1690) Next we want to compare our two selected years and determine the number who went up, down and stayed the same and how that relates to the petitions. This analysis is based on the empirical cumulative relative frequency.
To reproduce the analysis on the website we use the dplyr min_rank function (which is equivalent to rank(ties.method = “min”) in base R). This ranks all of the tax payments with gaps between the ties. So if two people are tied for the second rank, the person after them would be ranked fourth. Turn the rank into a percentile by subtracting 1 and dividing by the number of tax payers in that year.
comparison <- persisters |>
mutate(across(starts_with("X"),
list(
rank = min_rank
)
)) |>
filter(!is.na(X1690) & !is.na(X1681)) |>
mutate(
X1690_ptile = 100 * (X1690_rank - 1)/100,
X1681_ptile = 100* (X1681_rank - 1)/94,
compare_1681_1690 =
case_when(
X1690_ptile -X1681_ptile >= 10 ~ "Up",
X1690_ptile -X1681_ptile <= -10 ~ "Down",
TRUE ~ "No Change"
)
)
table(comparison$compare_1681_1690, comparison$Petition,
dnn = c("Change", "Petition")) |>
kable(caption = "Change in position 1681-1690")| Anti-P | NoS | Pro-P | |
|---|---|---|---|
| Down | 7 | 2 | 4 |
| No Change | 10 | 2 | 8 |
| Up | 7 | 2 | 9 |
Conclusion
This has illustrated how to reproduce the analyses from the Salem Witchcraft Website. The raw data is available at the websie and at the respository for this package. The code used to transform the original data into the files presented here is also available at that location.